


Stop Guessing Pod Sizes. Start Predicting.
Thoras uses machine learning to forecast what your pods actually need and adjusts CPU and memory before demand changes. No restarts. No OOMs. No over provisioning.
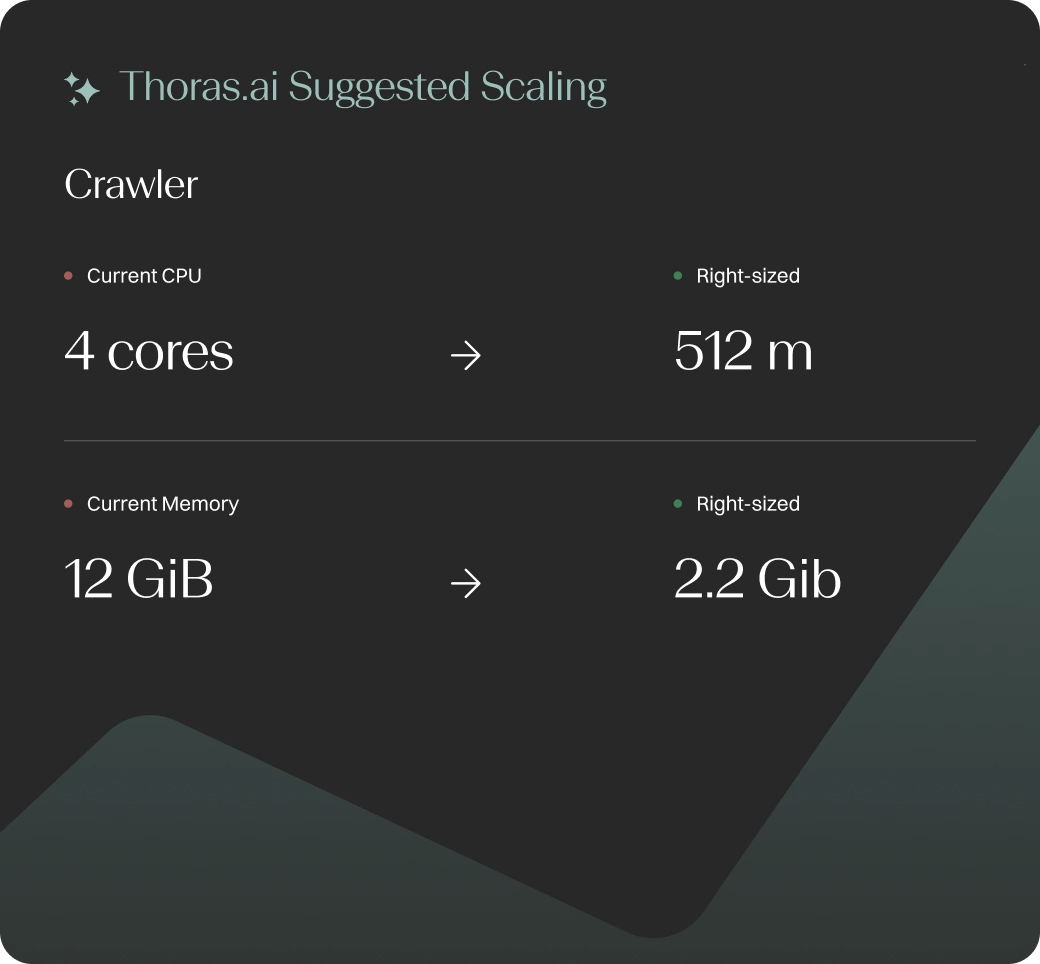

Results You Can Expect
30–70%
reduction from CPU and memory rightsizing
Zero Restarts
for right-sizing adjustments on supported workloads
Achieve ~85% Utilization
while reducing node scheduling inefficiencies and memory pressure.
Entirely Air-Gapped & Installs In 15 minutes
.svg)
Tailored to Your Needs
Thoras continuously analyzes CPU, memory, and request load across your services to understand when and how traffic actually spikes and ensure you have enough compute at the right time.

ML-driven Predictions
When demand is about to rise, we adjust resource requests before the spike, not after. When demand drops, we release the excess capacity you no longer need.
.svg)
Automatically Right-sized
No more manual sizing for max capacity. No threshold babysitting. Thoras keeps your pods fitted to actual demand autonomously, 24/7.
Why Predictive Right-Sizing Matters
.svg)
The VPA Problem
Kubernetes VPA restarts pods to apply new resource settings. For single-replica workloads or latency-sensitive services, that’s a non-starter. Not only that, but VPA doesn’t play well with HPA. You often have to choose one or the other.
.svg)
The Thoras Difference
Thoras predicts demand minutes or hours ahead of time (can be user-defined). Predictions coupled with real-time monitoring drive our autonomous resource scaling horizontally, vertically, or both while also leverage in-place rightsizing to scale without the need for restarts.
Trusted by Engineers That Can’t Afford Mistakes






Ready to optimize your bursty workloads?
Take back your sleep.
No more guesswork, no more 2 AM fire drills — just the right capacity, the right data, at the right time.
Book a Demo




© 2025 Thoras.ai. All rights reserved.