



Human-Centered Pull Requests: What Most PR Advice Is Missing
Staying Ahead of the Spike: How Mux Scales Before Traffic Hits

.jpg)
HQ:
San Francisco
Industry:
Video infrastructure
Table of contents
Mux powers video infrastructure and analytics for some of the world's most recognizable brands. From the Big Game, to viral livestreams, and all the day-to-day traffic in between, the operational burden of scaling is no joke.
For Mux, whose event collection system processes massive volumes of video data and telemetry, the stakes are high. If their systems go down or get overwhelmed, customers could experience disrupted content delivery, degraded live stream quality, or loss of critical monitoring capabilities. Until recently, managing this constant scaling challenge meant making a tough choice between reliability and cost efficiency.
The Challenge: Reactive Scaling Can't Keep Up
Like many companies running Kubernetes workloads at scale, Mux relies on horizontal pod autoscaling (HPA) for scaling decisions. The problem? HPA is fundamentally reactive. It waits for traffic to arrive, then responds. By the time metrics trigger a scaling event, nodes and pods need time to spin up and become ready. For sudden traffic spikes, this delay can mean dropped requests, degraded service, or even an outage.
Managing scaling at this level required significant engineering attention. The team used a combination of monitoring, calendar-based planning, and hands-on intervention to stay ahead of traffic events. This was a workable approach, but required ongoing effort and created real tradeoffs. For truly massive events, proactive preparation could require spending more than a day of engineering time. And despite that investment, the team still faced a fundamental choice: overprovision infrastructure and absorb the cost, or run lean and accept the risk of incidents when traffic exceeded projections.
The Solution: Predictive Autoscaling
Mux needed a different approach. One that could anticipate traffic before it arrived. That's where Thoras' predictive autoscaling platform came in.
Rather than reacting to current metrics, Thoras uses machine learning to forecast workload demand and scale infrastructure proactively. The system analyzes historical traffic patterns, identifies recurring trends, and predicts future resource needs with enough lead time to have capacity ready before traffic increases. For Mux, this meant their Kubernetes clusters could automatically handle the routine daily and weekly fluctuations without constant human intervention, scaling up during North American peak hours, adjusting for regional patterns, and managing content launches seamlessly.
The implementation focused on Mux's most critical workload, their event collection system. After a staging period that built confidence in the predictions, Mux switched Thoras to "Autonomous Mode," allowing it to make scaling decisions automatically without manual approval. The system deployed as a Predictive HPA, working seamlessly within Mux's existing Kubernetes infrastructure.
Results: Reliability First
The impact on reliability was immediate and dramatic. Since deploying Thoras, Mux has experienced zero capacity-related incidents. The routine traffic variations that previously would have triggered alerts and paging now happen transparently, handled automatically by Thoras' predictive scaling system. Daily peak hours, regional traffic patterns, and content launches—all previously requiring active monitoring—now scale seamlessly without intervention.
The confidence boost has been transformative. "I think one of the biggest changes has been that teams don't even think much about it anymore," stated Brian Lieberman, Senior Software Engineer at Mux. "Implementing Thoras has been very transparent." Where engineers previously approached traffic fluctuations with constant vigilance, they now trust the system to maintain appropriate capacity.
Over the past year, only one event (Thanksgiving football) required a planned proactive adjustment outside what Thoras handled autonomously. For an event of that scale and visibility, Mux chose to layer in manual oversight as a precaution. Everything else, the predictable patterns that make up the vast majority of scaling needs are handled autonomously. The system maintains service quality throughout normal operations, protecting customers' brand reputation and ensuring reliable delivery of live streams, on-demand content, and monitoring data.
Results: Engineering Freedom
Beyond preventing incidents, predictive autoscaling freed Mux's engineering team from constant operational overhead. Engineers no longer monitor dashboards anxiously during routine traffic fluctuations, trusting the system to maintain capacity automatically.
Most importantly, the on-call burden decreased significantly. The pages for manual scaling interventions that previously interrupted engineers day and night have largely disappeared. Those on-call can now focus on actual issues rather than routine capacity management. The mental overhead of constantly thinking about scaling decisions largely vanished, allowing the team to redirect their energy toward building features and improving products.
Results: Cost Efficiency as a Bonus
While reliability was the primary driver, the cost benefits proved substantial. By using Thoras' predictive scaling, Mux safely increased workload utilization from 50% to 80% for their primary event collection service. This resulted in a 38% reduction in compute footprint, which was a dramatic decrease in cloud spending.
These metrics highlight the impact of switching to Autonomous Mode in April:
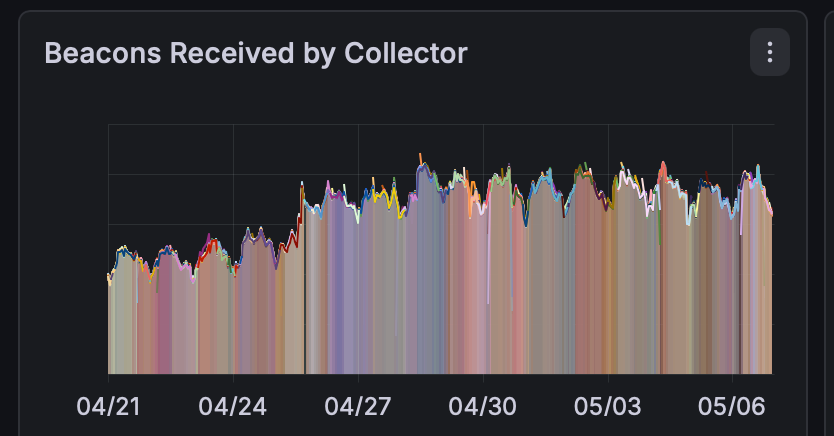
Improved efficiency across each Collector
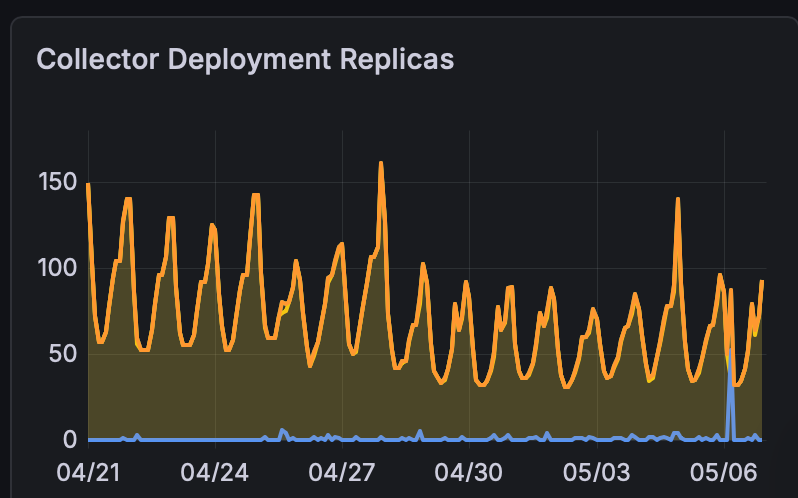
Fewer pods required to handle the same usage
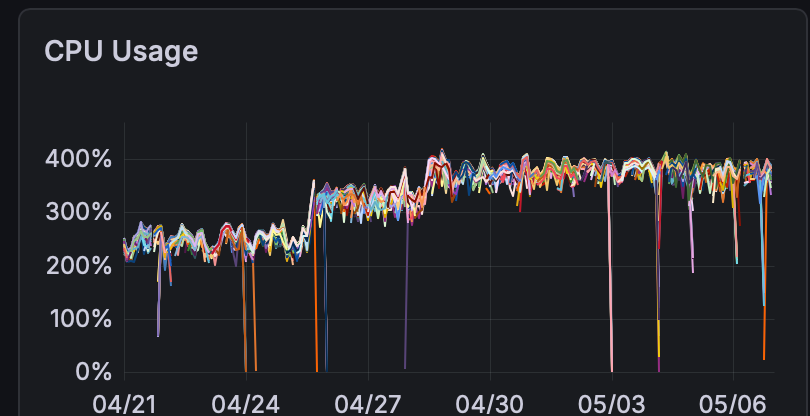
Improved CPU utilization
Previously, maintaining the safety buffer meant running significantly overprovisioned to handle the constant traffic variability without manual intervention. With predictive scaling handling routine patterns reliably, Mux could run much leaner throughout the day. The higher utilization became safe because the system continuously adjusted capacity to match the predictable ebb and flow of traffic.
The cost savings contribute directly to Mux's company-wide cost optimization goals and enable them to pass savings on to their customers.
Looking ahead, Mux plans to implement in-place vertical right-sizing for their resource-intensive, stateful workloads. This will optimize not just the number of pods, but the CPU and memory allocated to each, further reducing waste while maintaining reliability.
A True Partnership
Beyond the technical results, Mux emphasized the quality of the partnership itself. "The relationship was above and beyond what you expect from most vendors," noted Ron Lipke, Senior Engineering Manager at Mux. "The responsiveness and genuine investment in our success made it feel less like a vendor relationship and more like a true partnership."
For companies running mission-critical Kubernetes workloads, the traditional tradeoff between reliability and cost no longer needs to be an either/or decision. Predictive autoscaling delivers both: proactive capacity management that prevents incidents while dramatically reducing cloud spend.
As Mux continues expanding Thoras across their infrastructure, their experience demonstrates a fundamental shift in how modern platforms can approach operational excellence. When your infrastructure anticipates demand rather than reacting to it, engineering teams gain the freedom to focus on what matters most: building great products for their customers.
Thoras AI is a Kubernetes workload management platform that optimizes efficiency and reliability by forecasting usage, right-sizing compute resources, and making proactive scaling decisions. Learn more at thoras.ai.
Trial Thoras for free, and start scaling immediately.
Take back your sleep.
No more guesswork, no more 2 AM fire drills — just the right capacity, the right data, at the right time.
Book a Demo




© 2025 Thoras.ai. All rights reserved.